Parsing the Price Property Register
Part 01: Eircode, County and Dublin Postcode
by Brian Lynch

Photo by Toa Heftiba on Unsplash
Introduction
The Residential Property Price Register is produced by the Property Services Regulatory Authority (PSRA) pursuant to section 86 of the Property Services (Regulation) Act 2011. It includes Date of Sale, Price and Address of all residential properties purchased in Ireland since the 1st January 2010, as declared to the Revenue Commissioners for stamp duty purposes.
Anyone who has attempted to work with the data from Ireland’s Price Property Register will know that the dataset can be a bit of a mess.
We will attempt to tidy it up by extracting structured data from the semi-structured address string.
By the end of this blog we will have improved almost 50% of the rows in the dataset.
Currently the dataset has approximatly 450,000 rows. The columns in the dataset are:
- Date of Sale
- Address
- Postal Code
- County
- Price
- Not Full Market Price
- VAT Exclusive
- Property Size Description
- Description of Property
The ones we are interested in are Address, Postal Code and County.
In many rows in the dataset, the Address can contain County information Postal Code information...or both.
Aim
Our aim is to remove this information from the address string and update the Postcode or County information where necessary.
Examples
| Address | Cleaned Data |
|---|---|
| 1 MEADOW AVENUE, DUNDRUM, DUBLIN 14 | address = 1 Meadow Avenue, Dundrum postcode=Dublin 14 |
| 44 ALLEN PARK ROAD, STILLORGAN, COUNTY DUBLIN | address = 44 Allen Park Road, Stillorgan county = Dublin |
| 1 INFIRMARY RD, DUBLIN 7, DUBLIN | address = 1 Infirmary rd postcode = Dublin 7 county = Dublin |
Tools for the job
- python
- pandas
- regex
- sqlite3
- Jupyter Notebooks
- DB Browser for sqlite
Method
Data preperation
PPR data is attained as a csv file. Pandas will be used to load the data, modify the column names and create a uuid for each row.
This will be exported to a sqlite database.
Address cleaning
First we will normalise the eircode, county and postal code substrings in each address. Each will be normalised to an easily extractable pattern.
Testing will be used to create the normalisation and extraction functions
regex will play a major role in creating these functions
Extraction will be done in order of structure
- Eircode: Rigid structure of a key followed by 4 alphanumeric characters
- Postcode: “Dublin” or “D” followed by a postcode number
- County: Different spellings of “county”, followed by County Name
Data Preperation
The PPR dataset can be downloaded here: https://propertypriceregister.ie/Website/NPSRA/pprweb.nsf/page/ppr-home-en
We will use pandas to prepare the data and save it to a sqlite database
import sqlite3import pandas as pdfrom hashlib import blake2b# load datadf = pd.read_csv("../data/raw/PPR-ALL.csv", encoding='latin-1')# rename columnsdf = df.rename(columns={ 'Date of Sale (dd/mm/yyyy)': 'date', 'Address': 'address', 'Postal Code': 'postcode', 'County': 'county', 'Price (\x80)': 'price', 'Not Full Market Price': 'not_full_market_price', 'VAT Exclusive': 'vat_exclusive', 'Property Size Description': 'floor_area', 'Description of Property': 'construction',})# create uuid for each rowfor row in df.copy().itertuples(): hash_id_string = f"{row.date}{row.address}{row.postcode}{row.county}{row.price}{row.not_full_market_price}{row.vat_exclusive}{row.floor_area}{row.construction}" df.at[row.Index, 'uuid'] = blake2b(bytes(hash_id_string, "utf-8"), digest_size=5).hexdigest()# remove duplicatesdf.drop_duplicates(inplace=True)# set index to 'uuid'df.set_index('uuid', inplace=True)db_url = "../data/database.db"conn = sqlite3.connect(db_url)cur = conn.cursor()df.to_sql('ppr_all', conn)cur.close()conn.close()Now we have the PPR data in a sqlite database.
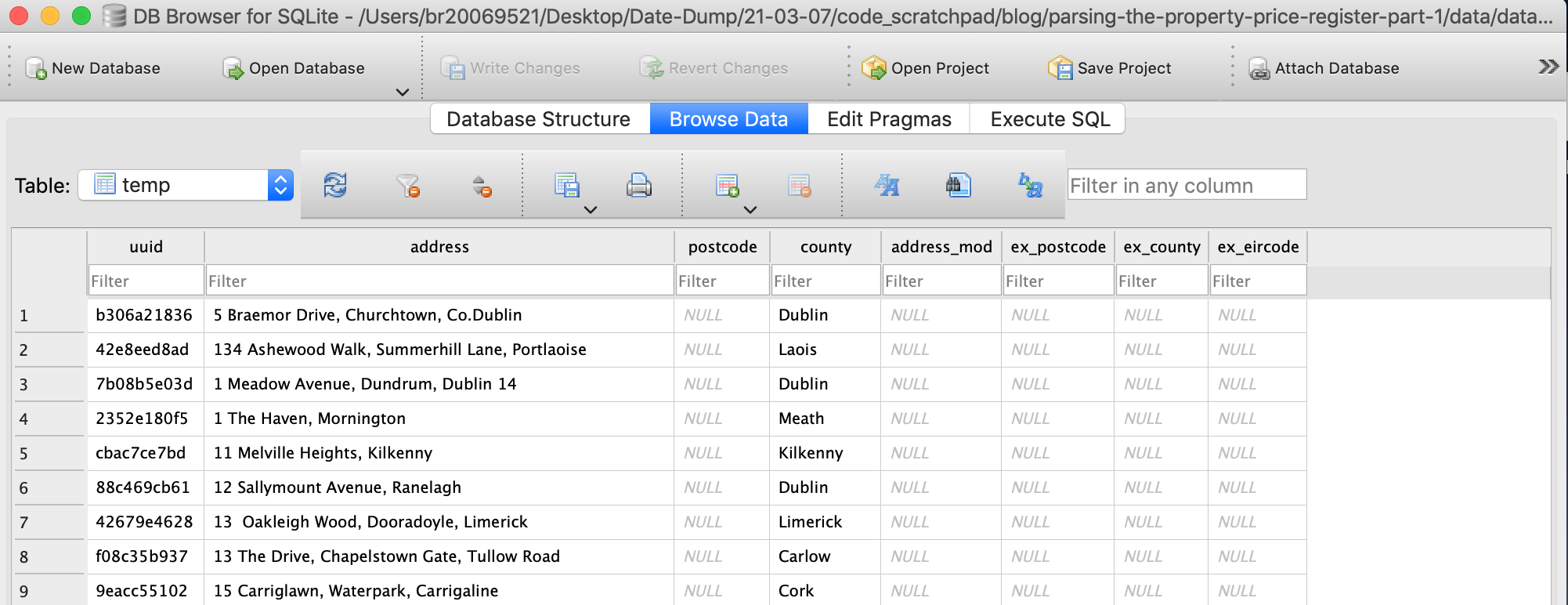
Create tempoary data table
We will create a temporary table to iterate over while we are creating the functions to normalise and extract data.
Dummy columns are added to store our extracted data.
To do this, we will again use pandas.
conn = sqlite3.connect('../data/database.db')df = pd.read_sql_query('SELECT * FROM ppr_all', conn)df.set_index('uuid', inplace=True)df = df.drop(["date","price","not_full_market_price","construction","floor_area","vat_exclusive"], axis=1)df.insert(3, 'ex_eircode', None)df.insert(3, 'ex_county', None)df.insert(3, 'ex_postcode', None)df.insert(3, 'address_mod', None)df.addresscur = conn.cursor()cur.execute(f"DROP TABLE IF EXISTS temp;")df.to_sql('temp', conn)cur.close()conn.close()Below is a view of the temp table created.
Eircode Extraction

Eircodes are quite structured, so there shouldn’t be a need to normalise the address before extraction.
There are 139 eircode routing keys, so we will look for one of these plus 4 succeeding alphanumeric characters.
Eircode routing keys can be found here: https://www.autoaddress.ie/blog/autoaddressblog/2016/09/21/eircode-routing-keys
Extract an Eircode from an address
First we will create some tests.
eircode extraction tests
def test_extract_eircode(self): self.assertEqual(ex.extract_eircode_from_end_of_address('1 Some Place, K67 KR86'), "K67 KR86") self.assertEqual(ex.extract_eircode_from_end_of_address('1 Some Place K67 KR86'), "K67 KR86") self.assertEqual(ex.extract_eircode_from_end_of_address('1 Some Place, K67KR86'), "K67 KR86")Now we will write our funciton to pass the tests.
eircode extraction function
xxxxxxxxxx
def extract_eircode_from_end_of_address(address: str): address = address.lower().strip(' ,.') eircode_routing_keys = [ 'a41', 'a42', 'a45', 'a63', 'a67', 'a75', 'a81', 'a82', 'a83', 'a84', 'a85', 'a86', 'a91', 'a92', 'a94', 'a96', 'a98', 'c15', 'd01', 'd02', 'd03', 'd04', 'd05', 'd06', 'd6w', 'd07', 'd08', 'd09', 'd10', 'd11', 'd12', 'd13', 'd14', 'd15', 'd16', 'd17', 'd18', 'd20', 'd22', 'd24', 'e21', 'e25', 'e32', 'e34', 'e41', 'e45', 'e53', 'e91', 'f12', 'f23', 'f26', 'f28', 'f31', 'f35', 'f42', 'f45', 'f52', 'f56', 'f91', 'f92', 'f93', 'f94', 'h12', 'h14', 'h16', 'h18', 'h23', 'h53', 'h54', 'h62', 'h65', 'h71', 'h91', 'k32', 'k34', 'k36', 'k45', 'k56', 'k67', 'k78', 'n37', 'n39', 'n41', 'n91', 'p12', 'p14', 'p17', 'p24', 'p25', 'p31', 'p32', 'p36', 'p43', 'p47', 'p51', 'p56', 'p61', 'p67', 'p72', 'p75', 'p81', 'p85', 'r14', 'r21', 'r32', 'r35', 'r42', 'r45', 'r51', 'r56', 'r93', 'r95', 't12', 't23', 't34', 't45', 't56', 'v14', 'v15', 'v23', 'v31', 'v35', 'v42', 'v92', 'v93', 'v94', 'v95', 'w12', 'w23', 'w34', 'w91', 'x35', 'x42', 'x91', 'y14', 'y21', 'y25', 'y34', 'y35' ] regex = r"\b(" + '|'.join(eircode_routing_keys) + r") ?([a-z0-9]{4})$" regex_result = re.search(regex, address) eircode = None if regex_result is not None: eircode = f"{regex_result.group(1)} {regex_result.group(2)}".upper() return eircodeEircode can now be successfully extracted from an address
Remove an Eircode from an address
Again, we will write test first.
eircode removal tests
def test_parse_address_of_eircode(self): self.assertEqual(pr.parse_address_of_eircode('1 Some Place, K67 KR86'), "1 Some Place") self.assertEqual(pr.parse_address_of_eircode('1 Some Place K67 KR86'), "1 Some Place") self.assertEqual(pr.parse_address_of_eircode('1 Some Place, K67KR86'), "1 Some Place")And now, we will write the function so all the tests pass. This workflow will be common throughout.
eircode removal function
xxxxxxxxxx
def parse_address_of_eircode(address: str): address = address.strip(' ,.') eircode_routing_keys = [ 'a41', 'a42', 'a45', 'a63', 'a67', 'a75', 'a81', 'a82', 'a83', 'a84', 'a85', 'a86', 'a91', 'a92', 'a94', 'a96', 'a98', 'c15', 'd01', 'd02', 'd03', 'd04', 'd05', 'd06', 'd6w', 'd07', 'd08', 'd09', 'd10', 'd11', 'd12', 'd13', 'd14', 'd15', 'd16', 'd17', 'd18', 'd20', 'd22', 'd24', 'e21', 'e25', 'e32', 'e34', 'e41', 'e45', 'e53', 'e91', 'f12', 'f23', 'f26', 'f28', 'f31', 'f35', 'f42', 'f45', 'f52', 'f56', 'f91', 'f92', 'f93', 'f94', 'h12', 'h14', 'h16', 'h18', 'h23', 'h53', 'h54', 'h62', 'h65', 'h71', 'h91', 'k32', 'k34', 'k36', 'k45', 'k56', 'k67', 'k78', 'n37', 'n39', 'n41', 'n91', 'p12', 'p14', 'p17', 'p24', 'p25', 'p31', 'p32', 'p36', 'p43', 'p47', 'p51', 'p56', 'p61', 'p67', 'p72', 'p75', 'p81', 'p85', 'r14', 'r21', 'r32', 'r35', 'r42', 'r45', 'r51', 'r56', 'r93', 'r95', 't12', 't23', 't34', 't45', 't56', 'v14', 'v15', 'v23', 'v31', 'v35', 'v42', 'v92', 'v93', 'v94', 'v95', 'w12', 'w23', 'w34', 'w91', 'x35', 'x42', 'x91', 'y14', 'y21', 'y25', 'y34', 'y35' ] regex = r"\b(" + '|'.join(eircode_routing_keys) + r") ?[a-z0-9]{4}$" address = re.sub(regex, '', address, flags=re.IGNORECASE).rstrip(', ') return addressEircode can now be successfully removed from an address
Extract Eircode from address
Now we will loop over the database and extract/remove eircode from address containing them.
xxxxxxxxxx
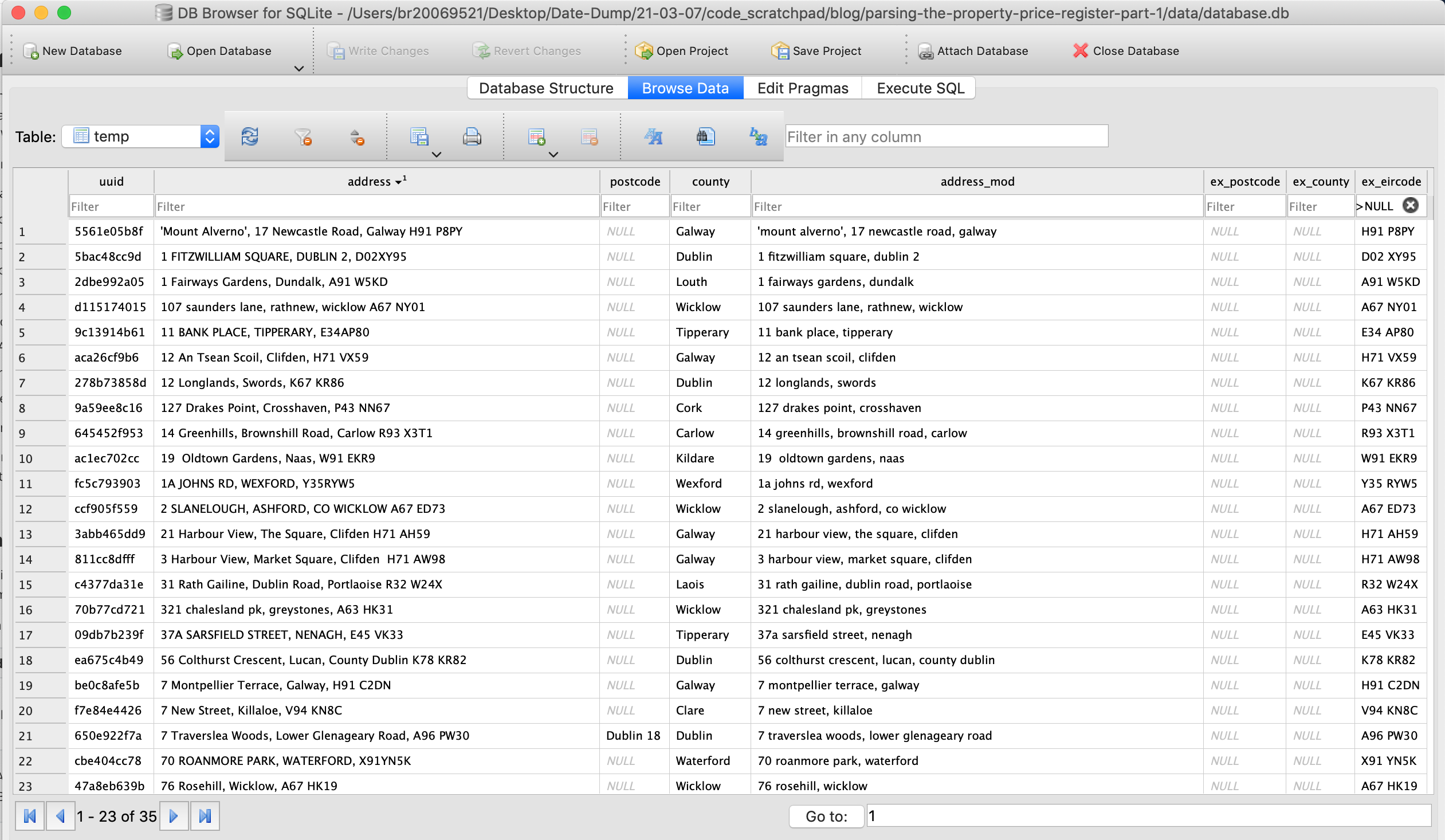
conn = sqlite3.connect('../data/database.db')df = pd.read_sql_query('SELECT * FROM temp;', conn)df.set_index('uuid', inplace=True)for row in df.copy().itertuples(): eircode = ex.extract_eircode_from_end_of_address(row.address_mod) if eircode is not None: df.at[row.Index, 'ex_eircode'] = eircode df.at[row.Index, 'address_mod'] = pr.parse_address_of_eircode(row.address_mod)cur = conn.cursor()cur.execute(f"DROP TABLE IF EXISTS temp;")df.to_sql('temp', conn)cur.close()conn.close()Now after opening the database, we can see we have sucessfully extracted 35 eircodes.
Considering Eircodes were introduced in July 2015, which accounts for over half of the rows in the database, this is a disappointing return.
Its is approximatly 0.0001% of address.
Dublin Postcode Extraction

Dublin postcodes are next in line in terms of structure. They are typically written as “Dublin” followed by the postcode number. This will not be the case for all addresses, so we will need to normalise the address before attempting extraction.
There are 22 Dublin postcodes, and a list can be found here: https://en.wikipedia.org/wiki/List_of_Dublin_postal_districts
Normalising the address for Dublin Postcodes
From scanning through the database, we have extracted some tests for our normalisation function. We will attempt to normalise each postcode to the format of dublin_{postcode_number}
Postcode normalisation tests
def test_normalise_dublin_postcode(self): self.assertEqual(nm.normalise_dublin_postcode('1 some place, dublin 4'), "1 some place, dublin_4") self.assertEqual(nm.normalise_dublin_postcode('1 some place, dublin 04'), "1 some place, dublin_4") self.assertEqual(nm.normalise_dublin_postcode('1 some place, dublin 14'), "1 some place, dublin_14") self.assertEqual(nm.normalise_dublin_postcode('1 some place, dublin 6w'), "1 some place, dublin_6w") self.assertEqual(nm.normalise_dublin_postcode('1 some place, dublin 6 west'), "1 some place, dublin_6w") self.assertEqual(nm.normalise_dublin_postcode('1 some place, dublin. 15'), "1 some place, dublin_15") self.assertEqual(nm.normalise_dublin_postcode('1 some place, dublin 15.'), "1 some place, dublin_15") self.assertEqual(nm.normalise_dublin_postcode('1 some place, d9'), "1 some place, dublin_9") self.assertEqual(nm.normalise_dublin_postcode('1 some place, d 15'), "1 some place, dublin_15") self.assertEqual(nm.normalise_dublin_postcode('1 some place, d/15'), "1 some place, dublin_15") self.assertEqual(nm.normalise_dublin_postcode('1 some place, d.15'), "1 some place, dublin_15") self.assertEqual(nm.normalise_dublin_postcode('1 some place, d. 15'), "1 some place, dublin_15") self.assertEqual(nm.normalise_dublin_postcode('1 place dublin 10, dublin 10'), "1 place, dublin_10") self.assertEqual(nm.normalise_dublin_postcode('1 place dublin 10, town'), "1 place dublin_10, town")Postcode normalisation function
xxxxxxxxxx
def normalise_dublin_postcode(address: str): address = address.lower().strip(',. ') address = re.sub(r'\bd(ublin)? *6 *(west|w)\b', 'dublin_6w', address) address = re.sub(r'dublin\.? 0?(\d+)', r'dublin_\1', address) address = re.sub(r" d[ /\.]*([012]?[0-9]w?)\b", r" dublin_\1", address) address = re.sub(r"\b(dublin_([12]?[0-9]w?)),? \1$", r", dublin_\2", address) address = re.sub(r" ?,[, ]+", r", ", address) return addressWe will run this function through or database to see how many address were normalised and search for outliers that aren’t represented in our tests.
xxxxxxxxxx
conn = sqlite3.connect('data/database.db')df = pd.read_sql_query('SELECT * FROM temp;', conn)df.set_index('uuid', inplace=True)df.address_mod = df.address_mod.apply(nm.normalise_dublin_postcode)cur = conn.cursor()cur.execute(f"DROP TABLE IF EXISTS temp;")df.to_sql('temp', conn)cur.close()conn.close()
Look for outliers
DB Browser for Sqlite allows for regex searching which is extremely useful for this.
Example: Search for misspellings of dublin with a number after (regex: /d[ublin ]*[\dw]+$/)
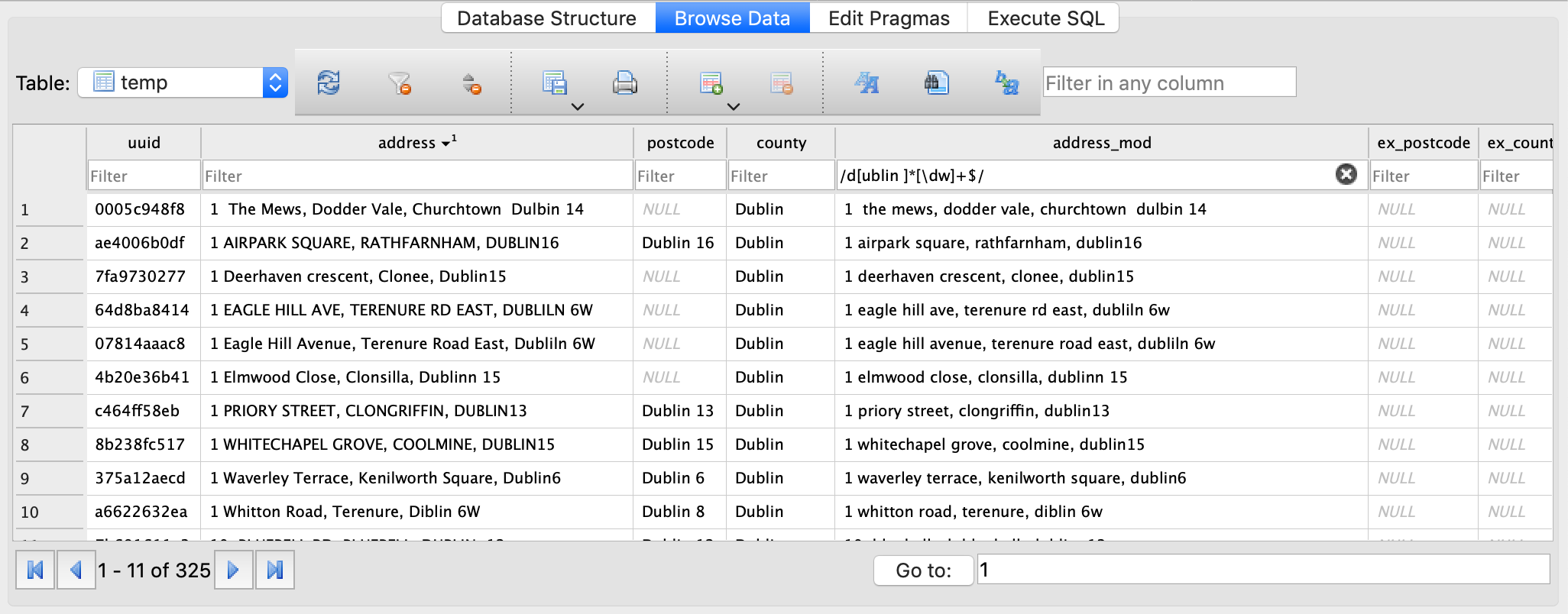
Here are some examples of rows that were not picked up by out original tests.
| address | error |
|---|---|
| 1 airpark square, rathfarnham, dublin16 | no space between dublin and number |
| 111 marlborough road, donnybrook, dublin 4 | double space between dublin and number |
| 11 the alders, carrington, santry dubllin 9 | misspelling of dublin |
We will add all outliers found to our tests
Postcode normalisation tests
xxxxxxxxxx
def test_normalise_dublin_postcode(self): self.assertEqual(nm.normalise_dublin_postcode('1 some place, dublin4'), "1 some place, dublin_4") self.assertEqual(nm.normalise_dublin_postcode('1 some place, dublin 4'), "1 some place, dublin_4") self.assertEqual(nm.normalise_dublin_postcode('1 some place, dublin 4'), "1 some place, dublin_4") self.assertEqual(nm.normalise_dublin_postcode('1 some place, dublin 04'), "1 some place, dublin_4") self.assertEqual(nm.normalise_dublin_postcode('1 some place, dublin 14'), "1 some place, dublin_14") self.assertEqual(nm.normalise_dublin_postcode('1 some place, dublin 6w'), "1 some place, dublin_6w") self.assertEqual(nm.normalise_dublin_postcode('1 some place, dublin 6 west'), "1 some place, dublin_6w") self.assertEqual(nm.normalise_dublin_postcode('1 some place, dublin. 15'), "1 some place, dublin_15") self.assertEqual(nm.normalise_dublin_postcode('1 some place, dublin 15.'), "1 some place, dublin_15") self.assertEqual(nm.normalise_dublin_postcode('1 some place, d9'), "1 some place, dublin_9") self.assertEqual(nm.normalise_dublin_postcode('1 some place, d 15'), "1 some place, dublin_15") self.assertEqual(nm.normalise_dublin_postcode('1 some place, d/15'), "1 some place, dublin_15") self.assertEqual(nm.normalise_dublin_postcode('1 some place, d.15'), "1 some place, dublin_15") self.assertEqual(nm.normalise_dublin_postcode('1 some place, d. 15'), "1 some place, dublin_15") self.assertEqual(nm.normalise_dublin_postcode('1 place dublin 10, dublin 10'), "1 place, dublin_10") self.assertEqual(nm.normalise_dublin_postcode('1 place dublin 10, town'), "1 place, dublin_10, town") self.assertEqual(nm.normalise_dublin_postcode('1 place, towndublin 6'), "1 place, town, dublin_6") # no change test self.assertEqual(nm.normalise_dublin_postcode('apt 58, block d2, town'), "apt 58, block d2, town") self.assertEqual(nm.normalise_dublin_postcode('apt d4, harvey dock, youghal'), "apt d4, harvey dock, youghal") self.assertEqual(nm.normalise_dublin_postcode('place, apt d07 student accom'), "place, apt d07 student accom") self.assertEqual(nm.normalise_dublin_postcode('apt d4, corm apts, foxford'), "apt d4, corm apts, foxford") # bad spellings self.assertEqual(nm.normalise_dublin_postcode('1 place, bublin 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dbulin 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, diblin 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, diblin 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dubiln 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dubin 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dublbin 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dubli 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dublini 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dublinn 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dubllin 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dubln 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dublni 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, duboin 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dulbin 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dulin 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dunlin 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dunlin6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dublihn 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dubkin 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dublihn 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, ddublin 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dubline 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dyublin 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dyublin 6'), "1 place, dublin_6") self.assertEqual(nm.normalise_dublin_postcode('1 place, dubglin 6'), "1 place, dublin_6")Now, we will update the postcode normalise function to make our new tests pass.
Postcode normalisation function
xxxxxxxxxx
def normalise_dublin_postcode(address: str): address = address.lower().strip(',. ') address = re.sub(r"(apt|block) +(d\d+)", r"\1==\2", address) address = re.sub(r"[, ]*\b[db]+y?[iunb]{1,2}[okgbil]{1,3}[nhei]{1,2} *(\d)", r", dublin \1", address) address = re.sub(r'\bd(ublin)? *6 *(west|w)\b', 'dublin_6w', address) address = re.sub(r'\bdublin\.? *0?(\d+)', r'dublin_\1', address) address = re.sub(r'([a-z]{3,})dublin\.? *0?(\d+)', r'\1, dublin_\2', address) address = re.sub(r" d[ /\.]*([012]?[0-9]w?)\b", r" dublin_\1", address) address = re.sub(r"\b(dublin_([12]?[0-9]w?)),? \1$", r", dublin_\2", address) address = re.sub(r" ?,[, ]+", r", ", address) address = re.sub("==", r" ", address) return addressHere is a link to the regex used for Dublin misspellings: https://regex101.com/r/GtTYKh/2
Now we have a robust function for normalising a Dublin Postcode in an address.
Extracting Dublin Postcode from an address
Dublin postcodes now have a consistent pattern in the address string. This makes it easy to extract them.
Postcode extraction tests
xxxxxxxxxx
def test_extract_dublin_postcode(self): self.assertEqual(ex.extract_dublin_postcode_from_address('1 some place, dublin_9'), "Dublin 9") self.assertEqual(ex.extract_dublin_postcode_from_address('1 some place, dublin_14'), "Dublin 14") self.assertEqual(ex.extract_dublin_postcode_from_address('1 some place, dublin_6w'), "Dublin 6W") self.assertEqual(ex.extract_dublin_postcode_from_address('1 place, dublin_10, town'), "Dublin 10") self.assertEqual(ex.extract_dublin_postcode_from_address('1 place, town, dublin_6'), "Dublin 6")Postcode extraction function
xxxxxxxxxx
def extract_dublin_postcode_from_address(address: str): address = address.lower().strip(' ,.') regex = r'dublin_(\d+w?)' regex_result = re.search(regex, address) postcode = None if regex_result is not None: postcode = f"Dublin {regex_result.group(1).upper()}" return postcodeNow we can successfully extract a Dublin Postcode from an address
Remove Dublin Postcode from an address
Postcode removal tests
xxxxxxxxxx
def test_parse_address_of_dublin_postcode(self): self.assertEqual(pr.parse_address_of_dublin_postcode('1 some place, dublin_9'), "1 some place") self.assertEqual(pr.parse_address_of_dublin_postcode('1 some place, dublin_14'), "1 some place") self.assertEqual(pr.parse_address_of_dublin_postcode('1 some place, dublin_6w'), "1 some place") self.assertEqual(pr.parse_address_of_dublin_postcode('1 place, dublin_10, town'), "1 place, town") self.assertEqual(pr.parse_address_of_dublin_postcode('1 place, town, dublin_6'), "1 place, town")Postcode removal function
xxxxxxxxxx
def parse_address_of_dublin_postcode(address: str): address = address.strip(' ,.') regex = r'dublin_(\d+w?)' address = re.sub(regex, ',', address, flags=re.IGNORECASE) address = re.sub(r"\s*,[,\s]+", ', ', address) return address.strip(',. ')Update database
We will loop over the database and extract/remove Dublin Postcodes from address containing them.
xxxxxxxxxx
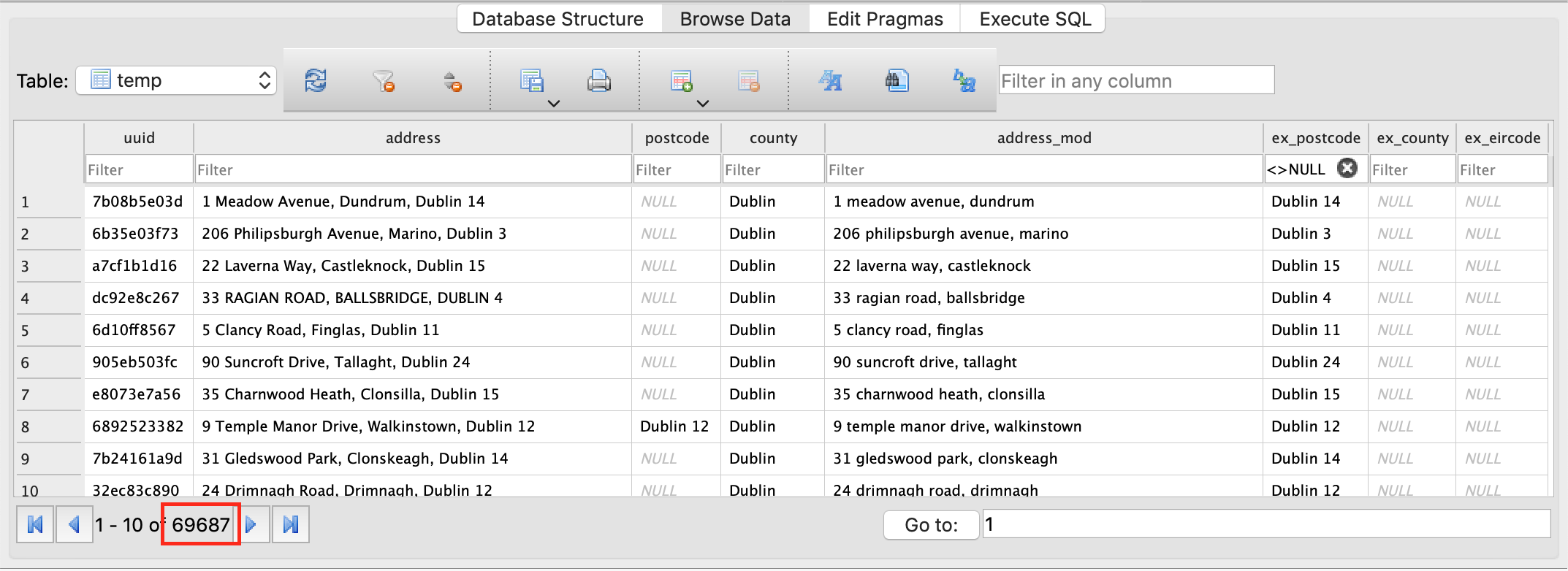
conn = sqlite3.connect('data/database.db')df = pd.read_sql_query('SELECT * FROM temp;', conn)df.set_index('uuid', inplace=True)df.address_mod = df.address_mod.apply(nm.normalise_dublin_postcode)for row in df.copy().itertuples(): postcode = ex.extract_dublin_postcode_from_address(row.address_mod) if postcode is not None: df.at[row.Index, 'ex_postcode'] = postcode df.at[row.Index, 'address_mod'] = pr.parse_address_of_dublin_postcode(row.address_mod)cur = conn.cursor()cur.execute(f"DROP TABLE IF EXISTS temp;")df.to_sql('temp', conn)cur.close()conn.close()Looking at the results in the database, we can see that 69,687 Dublin Postcodes have been extracted.
Considering sales in Dublin account for about 150,000 rows in the database, this is a great return.
County Extraction
Finally, we will attempt to extract the county name from the end on an address. This will be more complicated than the previous two extractions.
There are 26 counties in the database. Initially we will look for one of these these surrounded by a longhand/shorthand naming of county.
Normalise function
1 Some Place, co cork => 1 Some Place, co_cork
From scanning through the database, we have extracted some tests for our normalisation function. We are attempting to normalise county to co_{county_name}
County normalisation tests
xxxxxxxxxx
def test_normalise_county_name(self): self.assertEqual(nm.normalise_county_name('1 Some Place, co cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county_name('1 Some Place, co. cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county_name('1 Some Place, co.cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county_name('1 Some Place co cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county_name('1 Some Place co cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county_name('1 Some Place county cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county_name('1 Some Place countycork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county_name('1 Some Place cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county_name('1 Some Place cork.'), "1 some place, co_cork") self.assertEqual(nm.normalise_county_name('1 Some Place, cork'), "1 some place, co_cork")County normalisation function
xxxxxxxxxx
def normalise_county_name(address: str): counties = ['carlow', 'cavan', 'clare', 'cork', 'donegal', 'down', 'dublin', 'fermanagh', 'galway', 'kerry', 'kildare', 'kilkenny', 'laois', 'leitrim', 'limerick', 'longford', 'louth', 'mayo', 'meath', 'monaghan', 'offaly', 'roscommon', 'sligo', 'tipperary', 'waterford', 'westmeath', 'wexford', 'wicklow'] address = address.lower().strip(' ,.') counties_regex = r"(" + '|'.join(counties) + r")" address = re.sub(r"[ ,]+(county|co\.|co) *\.?" + counties_regex, r", co_\2", address) address = re.sub(r"[ ,]" + counties_regex + r" ?(county|co\.|co)\b", r", co_\1", address) address = re.sub(r" +" + counties_regex + r"$", r", co_\1", address) address = re.sub(r", ?" + counties_regex + r"$", r", co_\1", address) return addressLook for outliers
We will do some investigation into the database to find outliers. Again, we will use DB Browser for Sqlite regex search for this.
Search for County in address (regex: / (county|co\.?) [a-z]+$/)
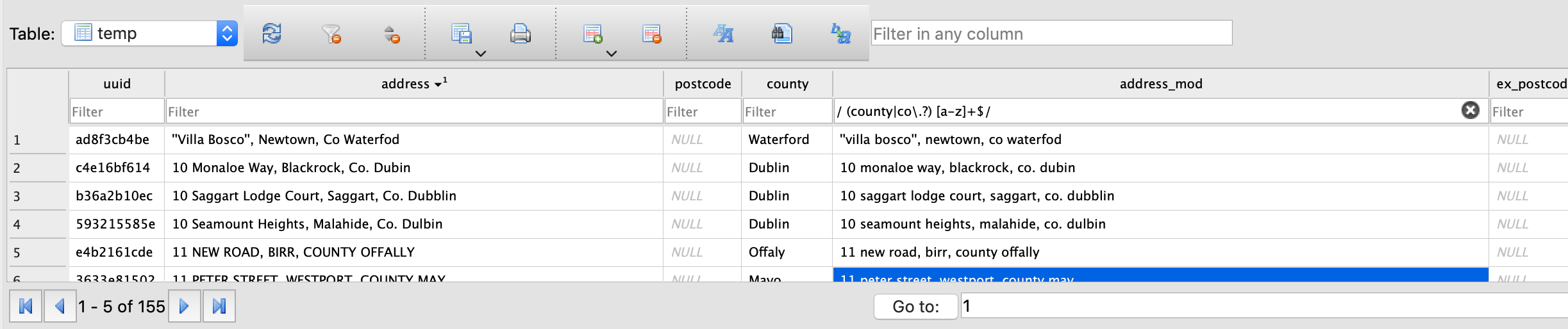
Seach for county names at the end of the address preceeded by a space
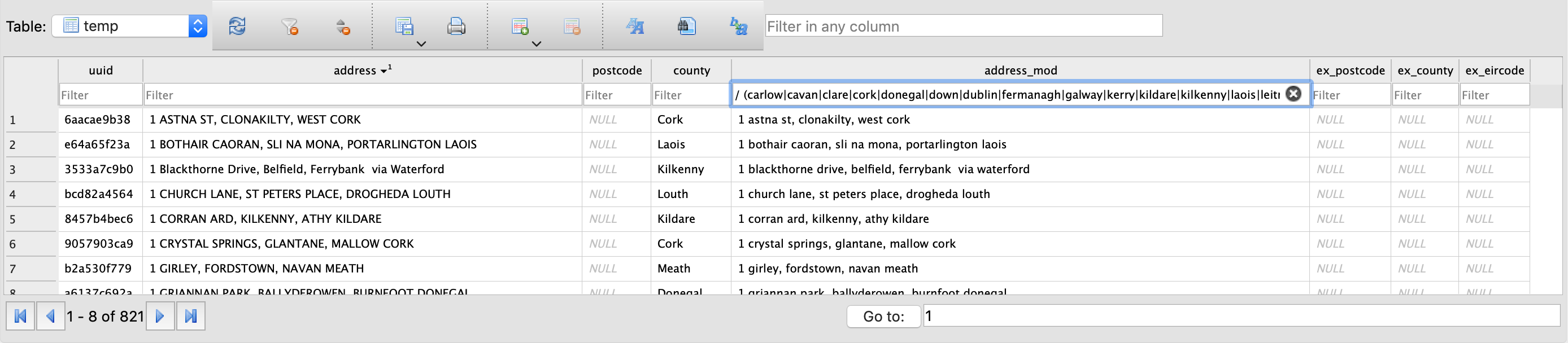
Between these two initial searches, we have found almost 1,000 outliers.
After futher investigation, there are numerous mistakes that we can correct. Here are a few that we missed:
| address | error |
|---|---|
| 8 ash park heath, lucan, cco. dublin | county prefix misspelling |
| 217 galloping green, stillorgan road, cunty dublin | county prefix misspelling |
| muckalee, ballyfoyle, cuonty kilkenny | county prefix misspelling |
| ballyrahan, tinahely, coounty wicklow | county prefix misspelling |
| st heliers, coast rd, fountainstownco cork | county prefix missing space |
| cloghoolia, sixmilebridge, county clqare | county name misspelling |
| ranafast, annagry, county donegak | county name misspelling |
| donore, multifarnham, west meath | county name misspelling |
| ballymacrown, baltimore, west cork | 'west cork' not needed in address as baltimore is a unique town |
| liskillea, waterfall, near cork | 'near' word unnecessary |
| springvale ballymaw, waterfall, near cork city | 'near' and 'city' words unnecessary |
If we updated our normalisation function to account for all these errors, it would potentially become difficult to read.
What we will do is split normalisation into three functions:
- normalise county spelling mistakes
- normalise county prefix spelling mistakes
- normalise county name and prefix to a searchable pattern
Normalise County Spelling
County spelling normalisation tests
Here is a subset of the tests written.
xxxxxxxxxx
def test_normalise_county_spelling(self): # = cork self.assertEqual(nm.normalise_county_spelling('1 some place, corl'), "1 some place, cork") self.assertEqual(nm.normalise_county_spelling('1 some place, cokr'), "1 some place, cork") self.assertEqual(nm.normalise_county_spelling('1 some place, crok'), "1 some place, cork") self.assertEqual(nm.normalise_county_spelling('1 some place, coork'), "1 some place, cork") # = donegal self.assertEqual(nm.normalise_county_spelling('1 some place, dongal'), "1 some place, donegal") self.assertEqual(nm.normalise_county_spelling('1 some place, doengal'), "1 some place, donegal") self.assertEqual(nm.normalise_county_spelling('1 some place, donegak'), "1 some place, donegal") # = dublin self.assertEqual(nm.normalise_county_spelling('1 some place, dubblin'), "1 some place, dublin") self.assertEqual(nm.normalise_county_spelling('1 some place, dubin'), "1 some place, dublin") self.assertEqual(nm.normalise_county_spelling('1 some place, dubliln'), "1 some place, dublin") self.assertEqual(nm.normalise_county_spelling('1 some place, dublibn'), "1 some place, dublin") self.assertEqual(nm.normalise_county_spelling('1 some place, dublibn'), "1 some place, dublin") self.assertEqual(nm.normalise_county_spelling('1 some place, dubllin'), "1 some place, dublin") .....County spelling normalisation function
There are several ways to normalise incorrect spelling. I have chosen to use regex.
xxxxxxxxxx
def normalise_county_spelling(address: str): address = re.sub(r" c[la][lqare]{2,3}e$", " clare", address) address = re.sub(r" [co][corkl]{1,3}[rkl]$", " cork", address) address = re.sub(r" do[nega]+[lk]$", " donegal", address) address = re.sub(r" du[bl][biln]{1,3}ni?$", " dublin", address) address = re.sub(r" g[al]{1,2}w[ayt]{1,3}$", " galway", address) address = re.sub(r" k[ilfd]{1,3}[dar]{1,3}[ed]$", " kildare", address) address = re.sub(r" ki[lk]{1,2}[ken]{2,4}[yt]$", " kilkenny", address) address = re.sub(r" loais$", " laois", address) address = re.sub(r" le[it]rim$", " leitrim", address) address = re.sub(r" l[im]{1,2}[eri]{1,3}c[fk]{1,2}$", " limerick", address) address = re.sub(r" lon[gfo]{1,3}[rds]{1,2}$", " longford", address) address = re.sub(r"(?<!the) l[ou][uthrg]+$", " louth", address) address = re.sub(r" m[maor]{1,2}[yo]{1,2}$", " mayo", address) address = re.sub(r" m[ae][aeth]+$", " meath", address) address = re.sub(r" m[oa][nagho]+$", " monaghan", address) address = re.sub(r" of[faly]+$", " offaly", address) address = re.sub(r" r[osd]{1,2}[cos]{1,3}mm[mon]{1,3}$", " roscommon", address) address = re.sub(r" s[li]{1,3}go$", " sligo", address) address = re.sub(r" tip{1,3}[eart]{1,5}y$", " tipperary", address) address = re.sub(r" wa[tr]er[forite]{1,4}d$", " waterford", address) address = re.sub(r" we[staer]{1,3}m[ea]{1,2}th$", " westmeath", address) address = re.sub(r"[, ]+(west) meath", r", westmeath", address) address = re.sub(r" w[ex]{1,2}[fv][fords]{1,3}$", " wexford", address) address = re.sub(r" w[ic]{1,3}[kl]{1,2}[ow]{1,2}$", " wicklow", address) return addressNormalise County Prefix Spelling
County prefix spelling normalisation tests
xxxxxxxxxx
def test_normalise_county_prefix_spelling(self): self.assertEqual(nm.normalise_county_prefix_spelling('1 some place, ci cork'), "1 some place, county cork") self.assertEqual(nm.normalise_county_prefix_spelling('1 some place, cp cork'), "1 some place, county cork") self.assertEqual(nm.normalise_county_prefix_spelling('1 some place, clo cork'), "1 some place, county cork") self.assertEqual(nm.normalise_county_prefix_spelling('1 some place, col cork'), "1 some place, county cork") self.assertEqual(nm.normalise_county_prefix_spelling('1 some place, ci cork'), "1 some place, county cork") self.assertEqual(nm.normalise_county_prefix_spelling('1 some place, cd cork'), "1 some place, county cork") self.assertEqual(nm.normalise_county_prefix_spelling('1 some place, ci cork'), "1 some place, county cork") self.assertEqual(nm.normalise_county_prefix_spelling('1 some place, c cork'), "1 some place, county cork") self.assertEqual(nm.normalise_county_prefix_spelling('1 some place, c0. cork'), "1 some place, county cork") self.assertEqual(nm.normalise_county_prefix_spelling('1 some place, cco. cork'), "1 some place, county cork") self.assertEqual(nm.normalise_county_prefix_spelling('1 some place, o cork'), "1 some place, county cork") self.assertEqual(nm.normalise_county_prefix_spelling('1 some place, cointy cork'), "1 some place, county cork") self.assertEqual(nm.normalise_county_prefix_spelling('1 some place, ccunty cork'), "1 some place, county cork") self.assertEqual(nm.normalise_county_prefix_spelling('1 some place, cunty cork'), "1 some place, county cork") self.assertEqual(nm.normalise_county_prefix_spelling('1 some place, couty cork'), "1 some place, county cork") self.assertEqual(nm.normalise_county_prefix_spelling('1 some place, couny cork'), "1 some place, county cork") self.assertEqual(nm.normalise_county_prefix_spelling('1 some place, count cork'), "1 some place, county cork") self.assertEqual(nm.normalise_county_prefix_spelling('1 some place, coutny cork'), "1 some place, county cork") self.assertEqual(nm.normalise_county_prefix_spelling('1 some place, countuy cork'), "1 some place, county cork") # negative self.assertEqual(nm.normalise_county_prefix_spelling('1 place, old dublin road'), "1 place, old dublin road") self.assertEqual(nm.normalise_county_prefix_spelling('1 place, i f s c dublin 1'), "1 place, ifsc, dublin 1")County prefix spelling normalisation function
xxxxxxxxxx
def normalise_county_prefix_spelling(address: str): counties = ['carlow', 'cavan', 'clare', 'cork', 'donegal', 'down', 'dublin', 'fermanagh', 'galway', 'kerry', 'kildare', 'kilkenny', 'laois', 'leitrim', 'limerick', 'longford', 'louth', 'mayo', 'meath', 'monaghan', 'offaly', 'roscommon', 'sligo', 'tipperary', 'waterford', 'westmeath', 'wexford', 'wicklow'] counties_regex = r"(" + '|'.join(counties) + r")" # mistakes address = re.sub(r" i f s c ", " ifsc, ", address) address = re.sub(r"[ ,]+c[oc]{0,1}[iun]{1,2}[tnuy]{1,3} *" + counties_regex, r", county \1", address) address = re.sub(r"[ ,]+c[doip0lc]{0,2} ?[\.\;\:]? *\.?" + counties_regex, r", county \1", address) address = re.sub(r"[ ,]+o " + counties_regex, r", county \1", address) address = re.sub(r"[ ,]" + counties_regex + r" ?(county|co\.|co)\b", r", county \1", address) address = re.sub(r"([a-z])(co\.?|county) " + counties_regex, r"\1, county \3", address) return addressNormalise County
Normalise County tests
xxxxxxxxxx
def test_normalise_county(self): self.assertEqual(nm.normalise_county('1 Some Place, co cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county('1 Some Place, co. cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county('1 Some Place, co . cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county('1 Some Place, co; cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county('1 Some Place, co: cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county('1 Some Place, co.cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county('1 Some Place co cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county('1 Some Place co cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county('1 Some Place county cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county('1 Some Place countycork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county('1 Some Place cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county('1 Some Place cork.'), "1 some place, co_cork") self.assertEqual(nm.normalise_county('1 Some Place, cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county('coast rd, fountainstownco cork'), "coast rd, fountainstown, co_cork") # part of a county self.assertEqual(nm.normalise_county('1 Some Place, west cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county('1 Some Place, nr cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county('1 Some Place, near cork'), "1 some place, co_cork") self.assertEqual(nm.normalise_county('1 Some Place, near cork city'), "1 some place, co_cork") self.assertEqual(nm.normalise_county('1 Some Place, north dublin'), "1 some place, co_dublin") self.assertEqual(nm.normalise_county('1 Some Place, north tipperary'), "1 some place, co_tipperary") self.assertEqual(nm.normalise_county('1 Some Place, south tipperary'), "1 some place, co_tipperary") self.assertEqual(nm.normalise_county('1 some place, city of dublin'), "1 some place, co_dublin") # county at end of address self.assertEqual(nm.normalise_county('1 Some Place tipperary'), "1 some place, co_tipperary") # remove mistakes self.assertEqual(nm.normalise_county('1 Some Place, co'), "1 some place") self.assertEqual(nm.normalise_county('1 Some Place, cork po'), "1 some place, co_cork") self.assertEqual(nm.normalise_county('1 Some Place, port laois'), "1 some place, portlaoise") self.assertEqual(nm.normalise_county('1 Some Place, port laoise'), "1 some place, portlaoise") # negative change self.assertEqual(nm.normalise_county('1 Some Place, the louth'), "1 some place, the louth") self.assertEqual(nm.normalise_county('1 Some Place, via louth'), "1 some place, via louth")Normalise County function
xxxxxxxxxx
def normalise_county(address: str): counties = ['carlow', 'cavan', 'clare', 'cork', 'donegal', 'down', 'dublin', 'fermanagh', 'galway', 'kerry', 'kildare', 'kilkenny', 'laois', 'leitrim', 'limerick', 'longford', 'louth', 'mayo', 'meath', 'monaghan', 'offaly', 'roscommon', 'sligo', 'tipperary', 'waterford', 'westmeath', 'wexford', 'wicklow'] counties_regex = r"(" + '|'.join(counties) + r")" address = address.lower().strip(' ,.') # mistakes address = re.sub(r" port laoise?$", " portlaoise", address) address = re.sub(r' po$', '', address) address = re.sub(r', co$', '', address) address = normalise_county_spelling(address) address = normalise_county_prefix_spelling(address) address = re.sub(r"county " + counties_regex + r"$", r"co_\1", address) address = re.sub(r" +" + counties_regex + r"$", r", co_\1", address) address = re.sub(r", ?" + counties_regex + r"$", r", co_\1", address) address = re.sub(r"[, ]+(west|near|nr) cork( city)?", r", co_cork", address) address = re.sub(r"[, ]+(north|south) tipperary", r", co_tipperary", address) address = re.sub(r"[, ]+(north) dublin", r", co_dublin", address) address = re.sub(r"[, ]+(city of dublin|dublin city)", r", co_dublin", address) address = re.sub(r"(?<!(the|via)) " + counties_regex + r"$", r", co_\2", address) return addressUpdate database
Now we will loop over the database and extract/remove County names from address containing them.
xxxxxxxxxx
conn = sqlite3.connect('data/database.db')df = pd.read_sql_query('SELECT * FROM temp;', conn)df.set_index('uuid', inplace=True)df.address_mod = df.address_mod.apply(nm.normalise_county)for row in df.copy().itertuples(): county = ex.extract_county_from_address(row.address_mod) if county is not None: df.at[row.Index, 'ex_county'] = county df.at[row.Index, 'address_mod'] = pr.parse_address_of_county(row.address_mod)cur = conn.cursor()cur.execute(f"DROP TABLE IF EXISTS temp;")df.to_sql('temp', conn)cur.close()conn.close()Looking at the database, we can see that 163,637 County names have been extracted.
This is approx 34% of rows in our database affected.
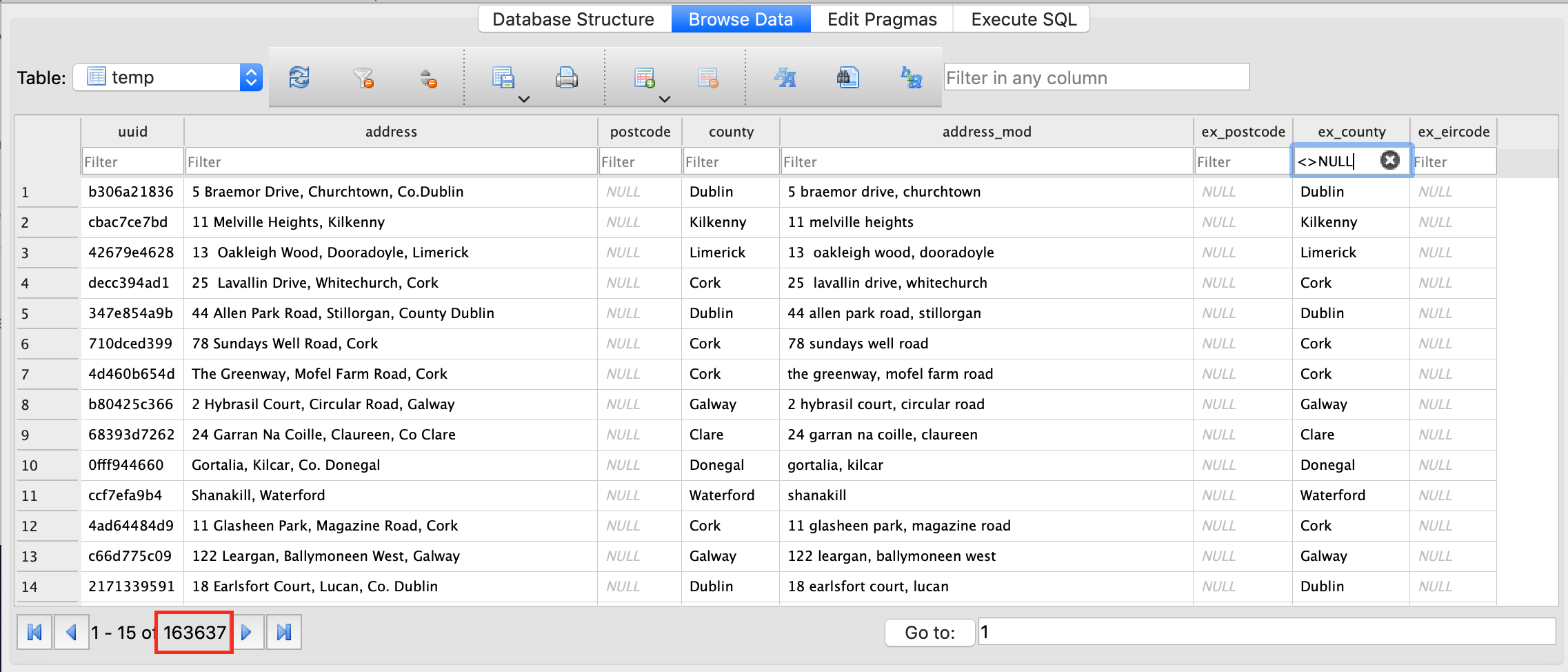
Combine Extracted Data with the origional Dataset
We have extracted either an Eircode, Dublin Postcode or County from 229,338 rows in the database.
We will now combine this data with the original dataset. In some cases, either the extracted County or Postcode won’t match what is in the County or Postcode column. In this case we will combine the two and comma-separate them.
Also, if we have extracted a Dublin Postcode from an address where the County is not listed as Dublin, we will add Dublin to the county column.
Theses rows that contain comma-separated values in the County or Dublin Postcode columns will have to be manually updated.
Get Origional Dataset as a pandas dataframe
We will add the updated address to its own column(address_mod).
It is useful to have the original when manually updating conflicts.
xxxxxxxxxx
conn = sqlite3.connect('data/database.db')df_orig = pd.read_sql_query('SELECT * FROM ppr_all;', conn)conn.close()df_orig.set_index('uuid', inplace=True)df_orig.insert(2, 'address_mod', None)df_orig.insert(5, 'eircode', None)df_orig.head()Combine Extracted Data
Eircode
xxxxxxxxxx
conn = sqlite3.connect('data/database.db')df = pd.read_sql_query('SELECT * FROM temp WHERE ex_eircode NOT NULL;', conn)for row in df.copy().itertuples(): df_orig.at[row.Index, 'address_mod'] = row.address_mod.title() df_orig.at[row.Index, 'eircode'] = row.ex_eircodeconn.close()Postcode
xxxxxxxxxx
conn = sqlite3.connect('data/database.db')df = pd.read_sql_query('SELECT * FROM temp WHERE ex_postcode NOT NULL;', conn)df.set_index('uuid', inplace=True)for row in df.copy().itertuples(): ex_postcode = row.ex_postcode postcode = row.postcode.title() county = row.county if postcode is None: df_orig.at[row.Index, 'postcode'] = row.ex_postcode if county != 'Dublin': df_orig.at[row.Index, 'county'] = f"{county}, (ex_postcode: Dublin)" else: if postcode != ex_postcode: df_orig.at[row.Index, 'postcode'] = f"{postcode}, (ex_postcode: {ex_postcode})" if county != 'Dublin': df_orig.at[row.Index, 'county'] = f"{county}, (ex_postcode: Dublin)" df_orig.at[row.Index, 'address_mod'] = row.address_mod.title()conn.close()County
xxxxxxxxxx
conn = sqlite3.connect('data/database.db')df = pd.read_sql_query('SELECT * FROM temp WHERE ex_county NOT NULL;', conn)df.set_index('uuid', inplace=True)for row in df.copy().itertuples(): ex_county = row.ex_county county = row.county if county != ex_county: df_orig.at[row.Index, 'county'] = f"{county}, (ex_county: {ex_county})" df_orig.at[row.Index, 'address_mod'] = row.address_mod.title() conn.close()Export Data to Sqlite DB
xxxxxxxxxx
conn = sqlite3.connect('data/database.db')cur = conn.cursor()cur.execute(f"DROP TABLE IF EXISTS ppr_all_mod;")df_orig.to_sql('ppr_all', conn)cur.close()conn.close()Conclusion
We set out to extract Eircode, Postcode and County from the address string in the Property Price Register. To do this we normalised the information in the string to add structure where it was missing.
Through a TDD approach, we were able to successfully extract:
35 Eircodes
69,687 Dublin Postcodes
163,637 Counties
This solution is not without its failings. There are conflicts due to inaccurate input of address, postcode or county in the original dataset.
The number of conflicts are:
2,068 Dublin Postcodes
1,038 Counties
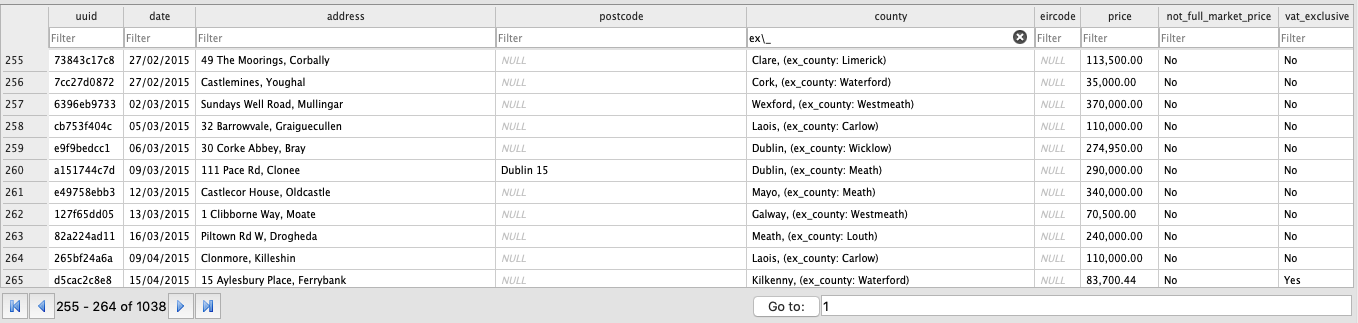
There are ways to reduce these conflicts programatically, but that's for another blog.
All the code for this blog is available to view on Github
This blog can also be read on Medium